퀵 정렬은 O(nlogn)의 시간복잡도를 가지는 빠른 정렬로써 데이터를 기준이 되는 숫자보다 작은 숫자와 큰 숫자로 왼쪽 오른쪽 분류해나가는 방식으로 동작한다. 여기서 기준이 되는 숫자를 pivot이라고 하고 이 pivot을 잡는 방법에 대해 설명하겠다.
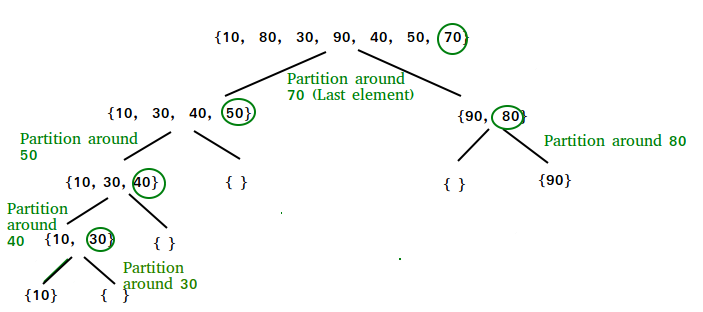
pivot의 선택은 어느 숫자로 잡아도 상관이 없다. 가장 처음 or 마지막 or 중간 등 어떠한 숫자로 잡아도 상관없지만 편의상 처음이나 중간, 마지막을 주로 사용한다. 위의 그림에서는 마지막을 피벗으로 잡았지만 코드에서는 가장 처음의 원소를 피벗으로 잡았다.
피벗을 잡게되면 이 피벗의 값을 기준으로 원소들의 크기를 비교하여 작은 값은 왼쪽에 더 큰 값을 오른쪽에 오도록 정렬한 뒤 이 피벗의 위치 값을 리턴한다.
이 리턴된 피벗값을 기준으로 왼쪽 범위, 오른쪽 범위로 다시 정렬할 대상이 나누어 지게 되고 다시 피벗을 잡고 분류하는 과정을 반복해 나간다. 범위의 left 인덱스와 right 인덱스의 값이 같아지면 결국 크기가 1인 배열로 최종적으로 나뉘어진 것이므로 더이상 진행하지 않는다.
위 그림의 예제를 보면 첫번째 단계에서 70을 기준으로 오른쪽 왼쪽 배열을 나누었고 70보다 더 작은 숫자는 {10 30 40 50}, 큰숫자는 {90,80}으로 나뉘어졌고 이 과정을 반복하는 것을 볼 수 있다. 퀵정렬의 시간복잡도가 nlong인 이유는 범위를 배열의 크기가 1일때 까지 나누는과정을 반복하는 logn과 피벗을 기준으로 분류하는 작업이 n이므로 nlogn의 시간복잡도를 가지게 된다.
퀵 정렬은 nlogn의 속도로 빠른 정렬에 속하지만 이미 정렬되어 있는 숫자에 대해 적용하면 O(n2)의 시간복잡도를 가질 수 있으므로 모두 정렬된 경우와 같은 상황에서는 효율을 기대할 수 없다.